🔊 We’ve been testing Resemble AI and ElevenLabs created voices – both sound completely human to me. I can’t hear the difference.
But Aleksei Aleshin ran the spectrogram analysis. The patterns jumped out immediately.
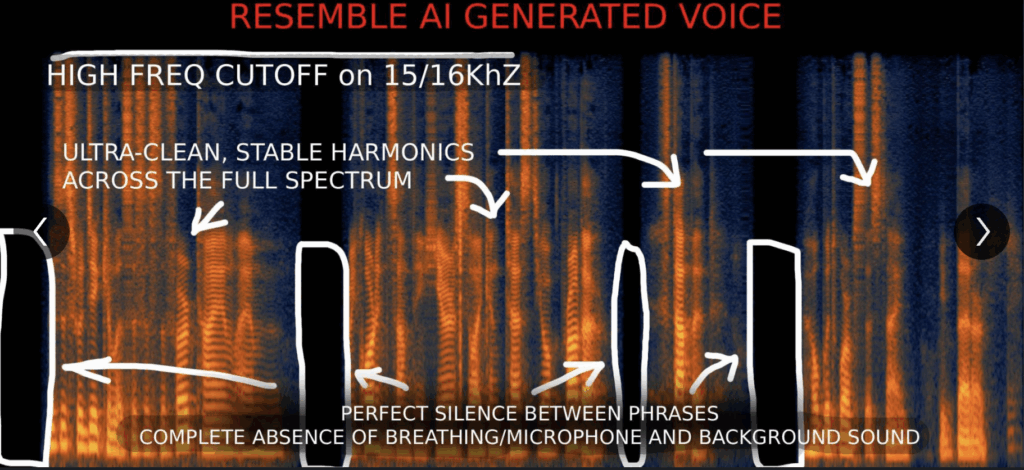
🎶 I’m sharing three spectrograms below: ElevenLabs, Resemble AI, and a real human voice. See for yourself!
What the spectrograms reveal:
👉 The “Too Perfect” Problem – both synthetic voices are smoother than humanly possible:
👉 Voice stability – The voice frequencies stay impossibly steady (look at those clean horizontal lines in the fake voices vs. the messy, imperfect ones in the real recording). ElevenLabs especially shows this.
👉Background consistency – Check the spaces between phrases. Real recordings are full of room tone, microphone noise, tiny ambient sounds. The synthetic ones are just uniform “haze” or complete silence.
Provider-Specific Signatures
👉 Resemble AI: Wave-like bending in the voice during sound transitions—their signature “wavy” pattern.
👉 ElevenLabs: Repeating “grid-like” pattern in higher pitches (above 6 kHz).
Both show “comb-like patterns” in high frequencies—but they manifest differently.
👉 The High-Frequency Cut-Off
Look at the top of the spectrograms. The synthetic voices have a straight-line cut-off at the high frequencies. The real voice? Messy, irregular, extends naturally.
👉 The Breathing Giveaway
ElevenLabs adds breathing for realism, but:
-> Too short (70 – 180 ms vs. natural 250 – 700 ms)
-> Too smooth (missing the chaotic airflow sound)
-> Abrupt start/stop (not gradual like real breathing)
-> Repetitive (nearly identical each time)
🎶 In the spectrograms: both synthetic samples are empty of breath sounds, or they’re too short. Compare that to the real voice where breathing is clearly visible and varied.
Even the most convincing synthetic voices leave fingerprints. For now, the more “realistic” features providers add, the more detection points they create.
Look at the three spectrograms below and see for yourself!