So, I was wondering how we can spot AI-created voices, in practice.
It’s awesome to have friends like Aleksei Aleshin, a sound engineer, who set up a quick experiment to detect voice deepfakes.
Here’s what he did:
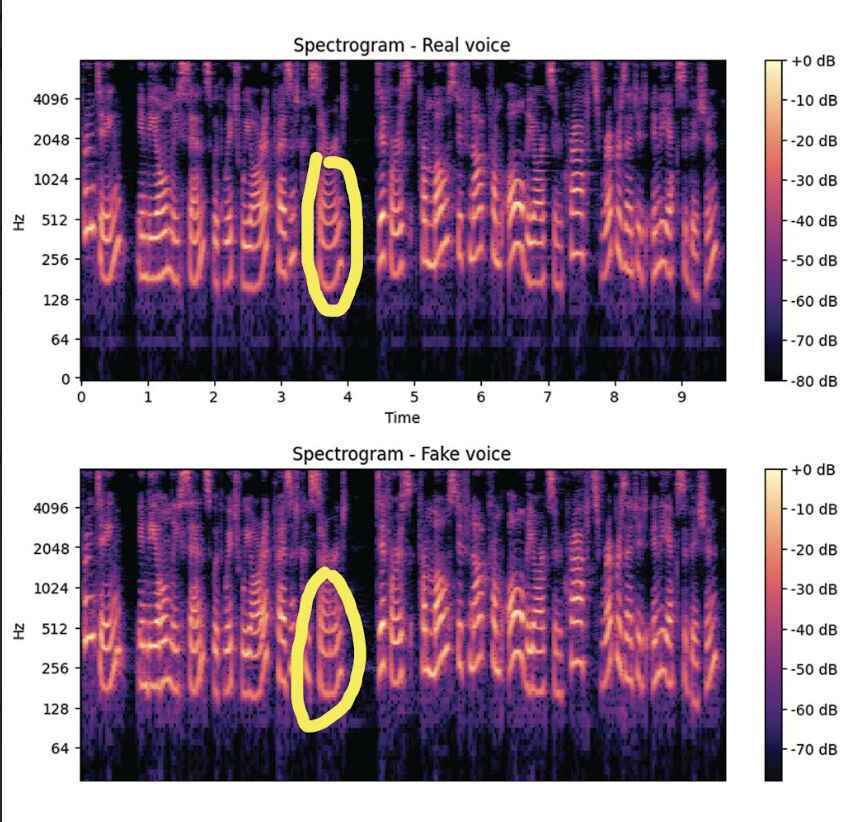
🔊He took several real and synthetic voices, used Python and Librosa to extract audio features (MFCC, spectrum, pitch, etc.), and compared spectrograms and pitch contours.
🎶 Even with a small dataset, the fake voices stood out—they were almost “too perfect,” with little pitch variation and unnaturally smooth patterns.
The most noticeable artifacts were visible on the spectrogram in Adobe Audition, and Aleksei Aleshin could hear them clearly. Honestly I couldn’t, which kind of worried me. 😬
❓So I asked myself if we are all becoming deepfake detectives, or will we rely on unified tools to protect us? Where does “obviously fake” end and “malicious intent” begin for detection tech?
We’re seeing new standards like C2PA for content authenticity, while detection tech struggles to separate harmless creativity from potential scams. The same deepfake tech used for entertainment is now being used for fraud.
As deepfakes become “obviously fake” to some and “convincingly real” to others, detection faces a big problem—intent matters but algorithms can’t read minds.
As AI voices improve, more sophisticated tools will be needed, and it will depend on the synthesis engine.
❓What do you think— how do we teach machines the difference between entertainment and exploitation?
hashtag#VoiceSecurity hashtag#Deepfakes hashtag#AI hashtag#ContentAuthenticity hashtag#DigitalTrust